From:
goroutine简介
golang语言作者Rob Pike说,“Goroutine是一个与其他goroutines 并发运行在同一地址空间的Go函数或方法。一个运行的程序由一个或更多个goroutine组成。它与线程、协程、进程等不同。它是一个goroutine“。
- goroutine通过通道来通信,而协程通过让出和恢复操作来通信;
- goroutine 通过Golang 的调度器进行调度,而协程通过程序本身调度;
简单的说就是Golang自己实现了协程并叫做goruntine(本文称Go协程),且比协程更强大。
goroutine调度原理
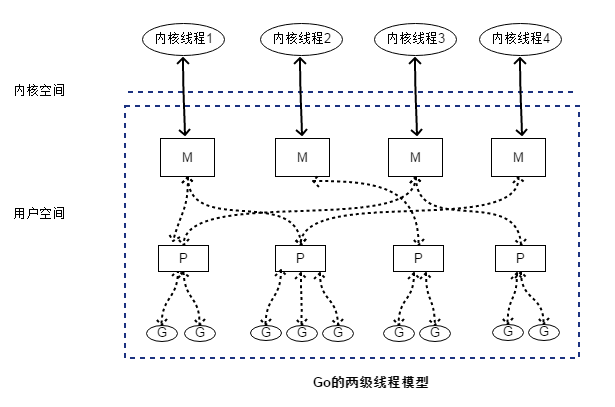
上面说到Go协程是通过Golang的调度器进行调度的,其中调度器的线程模型为两级线程模型。
有关两级线程模型的介绍,可以看文章最后。
我们来看下Golang实现的两级线程模型是怎样的。首先要知道这三个字母代表的含义
- M:代表内核级的线程
- P:全程Processor,代表运行Go协程所需要的资源(上下文环境)
- G:代表Go协程

我们先看下为实现调度Golang定义了这些数据结构存M,P,G
| 名称 | 作用范围 | 描述 |
|---|---|---|
| 全局M列表 | Go的运行时 | 存放所有M的单向链表 |
| 全局P列表 | Go的运行时 | 存放所有P的数组 |
| 全局G列表 | Go的运行时 | 存放所有G的切片 |
| 调度器的空闲M列表 | 调度器 | 存放空闲M的单向链表 |
| 调度器的空闲P列表 | 调度器 | 存放空闲P的单向链表 |
| 调度器的自由G列表 | 调度器 | 存放自由G的单向链表(有两个) |
| 调度器的可运行G队列 | 调度器 | 存放可运行G的队列 |
| P的自由G列表 | 本地P | 存放当前P中自由G的单向链表 |
| P的可运行G队列 | 本地P | 存放当前P中可运行G的队列 |
然后从上往下解析Go的两级线程模型图
- M和内核线程之间是一对一的关系,一个M在其生命周期中,只会和一个内核线程关联,所以不会出现对内核线程的频繁切换;
Golang的运行时执行系统监控和垃圾回收等任务时候会导致创建M,M空闲时不会被销毁,而是放到一个
调度器的空闲M列表中,等待与P关联,M默认数量为10000
- P和M之间是多对多的关系,P和G之间是一对多的关系,他们的关联是易变的,由Golang的调度器完成调度;
Golang的运行时按规则调度,让P和不同的M建立或断开关联,使得P中的G能够及时获得运行时机
- P的数量默认为CPU总核心数,最大为256,当P没有可运行的G时候(P的可运行G队列为空),P会被放到
调度器的空闲P列表中,等待M与它关联;
P有可能会被销毁,如运行时用runtime.GOMAXPROCS把P的数量从32降到16时,剩余16个会被销毁,它们原来的G会先转到调度器
可运行的G队列和自由G列表
- 每个P中有
可运行的G队列(如图中最下面的那行G)和自由G列表(图中未画出来),当G的代码执行完后,该G不会被销毁,而是被放到P的自由G列表或调度器的自由G列表。如果程序新建了Go协程,调度器会在自由G列表中取一个G,然后把Go协程的函数赋值到G中(如果自由G列表为空,就创建一个G);
可见Golang调度器在调度时很大程度复用了M,P,G
- 在Go程序初始化后,调度器首先进行一轮调度,此时用M去搜索可运行的G。其中我们的main函数也是一个G,找到可运行的G后就执行它;
至于怎么找可运行的G呢?答案是到处找,想尽办法找(这里只列出一部分地方)。
- 从
本地P的可运行的G队列找- 从
调度器的可运行的G队列找- 从
其他P的可运行的G队列找
P的可运行G队列最大只能存放长度为256的G,当队列满后,调度器会把一半的G转到调度器的可运行G队列。
系统监控
上面大概描述了关于goroutine调度的流程。现在还存在一个问题,那就是当Go协程很多(并发量大)时候,显然G是不能一直执行下去的,因为也需要把执行机会留给其他的G。此时Golang运行时的系统监控就起作用了。
一般情况,当G运行时间超过10ms后,该G就会被系统告知需要停止了,让其他G运行。(这里情况比较复杂,并不能确保每个G都能被公平执行)
以下特殊情况该G不需要停止
- P的可运行G队列为空(没有其他G可运行)
- 有空闲的M在寻找可运行的G(没有其他G可运行)
- 空闲的P(还有P闲着)
总结
Golang以两级线程实现模型,自己实现goruntine和调度器,优势在于并行和非常低的资源使用。
主要体现
- 内存消耗方面(每个Go协程占的内存远小于线程占的内存)
- 切换(调度)开销方面
- 线程切换涉及模式切换(从用户态切换到内核态)
此外,Go协程执行任务完成的顺序并不都是按我们预期的那样(程序不加以控制的情况下),特别在一些耗时较长的任务中。且每个Go协程执行的时间也不是绝对公平的。
线程实现模型
线程实现模型主要分为:用户级线程模型,内核级线程模型和两级线程模型。他们的区别在于线程与内核线程之间的对应关系。
以下我们将分析这三种线程实现模型的特点:
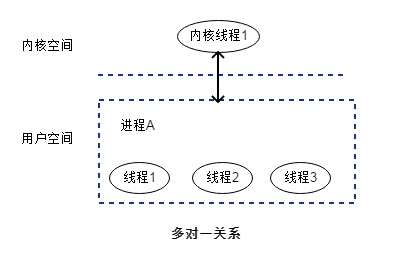
用户级线程模型
- 多对一关系
用户级线程模型为多对一关系。即,一个进程中的所有线程对应一个内核线程; - 处理速度快、移植性强;
线程的创建、调度、同步等操作由应用程序来处理,不需要让CPU从用户态切换到内核态。所以用户级线程模型在速度快,且移植性强; - 并非真正的并发运行
如果线程IO操作过程中被阻塞,那么用户空间的其他线程都会被阻塞,因为这些线程无法被内核调度。
内核级线程模型
(1)一对一关系
内核级线程模型为一对一关系,一个用户线程对应一个内核线程;
(2)资源消耗较大,速度较慢
进程对线程的创建、终止、切换和同步都必须通过内核提供的系统调用来完成,对内核的调度的调度器造成很大的负担;
(3)是真正的并发运行
用户线程和内核线程是一对一的关系,线程由内核来管理和调度。当某一线程阻塞时候,不会影响到其他线程。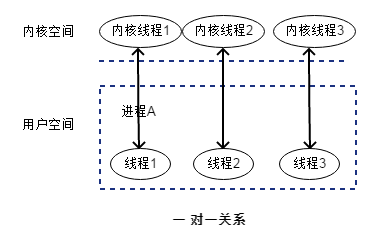
两级线程模型
- 多对多的关系
两级线程模型是集前面两种模型的优点而设计的,是多对多的关系; - 资源消耗较小,速度较快,是真正的并发运行
两级线程模型中,一个进程对应多个内核线程,进程中的线程由程序管理和调度并通过映射关系映射到内核线程上。这样即便有线程阻塞后,也不会影响到其他线程; - 实现的复杂度大
用户线程与内核线程的映射关系需要程序来实现,实现的复杂度大。幸运的是,Golang为我们实现了两级线程模型,这使得它在处理并发问题上更有优势。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。
